- 以3.10版本内核为例,4.1+版本内核在处理FIN-WAIT-2时有所改变,后面会提到
- 代码做适度精简
TL;DR
- Linux TCP的TIME_WAIT状态超时默认为60秒,不可修改
- Linux TCP的FIN_WAIT_2和TIME_WAIT共用一套实现
- 可以通过tcp_fin_timeout修改FIN_WAIT_2的超时
- 3.10内核和4.1+内核对tcp_fin_timeout实现机制有所变化
- reuse和recycle都需要开启timestamp,对NAT不友好
- 推荐使用4.3+内核,参数配置可以看最后

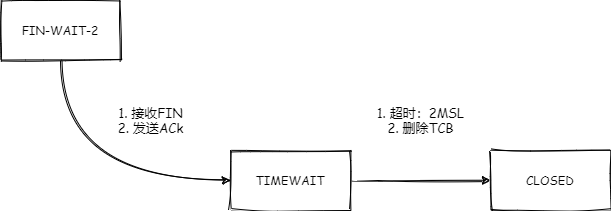
图1. TCP 状态机
源码解析
入口
初步认为tcp_input.c#tcp_fin为此次的入口,主动断开连接方收到被关闭方发出的FIN指令后,进入time-wait状态做进一步处理。
link:linux/net/ipv4/tcp_input.c
1 | /* |
处理time-wait
在tcp_minisocks.c中,会处理状态回收,控制time-wait桶大小等,先在这里给出结论:
a)net.ipv4.tcp_tw_recycle需要和net.ipv4.tcp_timestamps同时打开才可以快速回收
b) 连接状态为TIME_WAIT时,清理时间为默认60s,不可修改
link:linux/net/ipv4/tcp_minisocks.c
1 | // tcp_death_row 结构 |
time-wait轮询处理
根据timeo值大小计算slot,判断后,进入不同的timer,等待清理
1 | /* |
4.1+内核修改了什么
4.1 的内核,对TIME_WAIT处理逻辑做了改动,具体改动见PR,这里做一下简单翻译。
1 | tcp/dccp:摆脱单独一个time-wait timer |
commit:789f558cfb3680aeb52de137418637f6b04b7d22
link:v4.1/net/ipv4/inet_timewait_sock.c
1 | void inet_twsk_schedule(struct inet_timewait_sock *tw, const int timeo) |
然后在4.3对上面的PR又做了修订 ,详细见PR。做下简单翻译:
1 | 当创建一个timewait socket时,我们需要在允许其他CPU找到它之前配置计时器。 |
commit:ed2e923945892a8372ab70d2f61d364b0b6d9054
link:v4.3/net/ipv4/inet_timewait_sock.c#L222
1 | void __inet_twsk_schedule(struct inet_timewait_sock *tw, int timeo, bool rearm) |
简单来说,就是CPU利用率提升,吞吐量提高。推荐使用4.3+内核
几个常见参数介绍
net.ipv4.tcp_tw_reuse
重用 TIME_WAIT 连接的条件:
- 设置了 tcp_timestamps = 1,即开启状态。
- 设置了 tcp_tw_reuse = 1,即开启状态。
- 新连接的 timestamp 大于 之前连接的 timestamp 。
- 在处于 TIME_WAIT 状态并且持续 1 秒之后。
get_seconds() - tcptw->tw_ts_recent_stamp > 1。
重用的连接类型:仅仅只是 Outbound (Outgoing) connection ,对于 Inbound connection 不会重用。
安全指的是什么:
- TIME_WAIT 可以避免重复发送的数据包被后续的连接错误的接收,由于 timestamp 机制的存在,重复的数据包会直接丢弃掉。
- TIME_WAIT 能够确保被动连接的一方,不会由于主动连接的一方发送的最后一个 ACK 数据包丢失(比如网络延迟导致的丢包)之后,一直停留在 LAST_ACK 状态,导致被动关闭方无法正确地关闭连接。为了确保这一机制,主动关闭的一方会一直重传( retransmit ) FIN 数据包。
1 | int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp) |
net.ipv4.tcp_tw_recycle
详见上面处理time-wait一节的分析
不建议开启 tw_recycle 配置。事实上,在 linux 内核 4.12 版本,已经去掉了 net.ipv4.tcp_tw_recycle 参数了,参考commit
tcp_max_tw_buckets
设置 TIME_WAIT 最大数量。目的为了阻止一些简单的DoS攻击,平常不要人为的降低它。如果缩小了它,那么系统会将多余的TIME_WAIT删除掉,日志里会显示:「TCP: time wait bucket table overflow」。
如何设置正确的值
定时器精度相关分析请看参考[3]
4.1内核
- tcp_fin_timeout <= 3, FIN_WAIT_2 状态超时时间为 tcp_fin_timeout 值。
- 3<tcp_fin_timeout <=60, FIN_WAIT_2状态超时时间为 tcp_fin_timeout值+定时器精度(以7秒为单位)误差时间。
- tcp_fin_timeout > 60, FIN_WAIT_2状态会先经历keepalive状态,持续时间为tmo=tcp_fin_timeout-60值, 再经历timewait状态,持续时间为 (tcp_fin_timeout -60)+定时器精度,这里的定时器精度根据(tcp_fin_timeout -60)的计算值,会最终落在上述两个精度范围(1/8秒为单位或7秒为单位)。
4.3+内核
- tcp_fin_timeout <=60, FIN_WAIT_2 状态超时时间为 tcp_fin_timeout 值。
- tcp_fin_timeout > 60, FIN_WAIT_2 状态会先经历 keepalive 状态,持续时间为 tmo=tcp_fin_timeout-60 值 , 再经历 timewait 状态,持续时间同样为 tmo= tcp_fin_timeout-60 值。
参考
[1] Linux TCP Finwait2/Timewait状态要义浅析,https://blog.csdn.net/dog250/article/details/81582604
[2] TCP的TIME_WAIT快速回收与重用,https://blog.csdn.net/dog250/article/details/13760985
[3] 由优化FIN_WAIT_2状态超时引入的关于tcp_fin_timeout参数研究,https://www.talkwithtrend.com/Article/251641
[4] TCP TIME_WAIT 详解,https://www.zhuxiaodong.net/2018/tcp-time-wait-instruction/
